Pages in this section:
All sections:
Auto-coding using AI: writing the instructions
This exciting new possibility to do auto coding at Causal Map is invitation only at the moment.
See also 🤖 Auto-coding: settings
The coding prompt
The default prompt is a sort of generic prompt, which gives instructions to chat GPT API to recode the file in a very generic way.
Even this generic way works quite nicely.
Study the results of your work in The Responses tab.
Sentences coding versus phrases coding
With sentences coding, you have to be careful that the AI does not include causal connections in the labels themselves, e.g.
Trainers encourage teachers to give the children extra time, and the children really improve.
If you aren’t careful, this could get coded like this:
Trainers encourage teachers to give the children extra time >> the children really improve.
Here there is a missing step. It should be something like this:
Trainers encourage teachers >> Teachers give extra time to children >> Children really improve
Make sure you clarify this in the original instruction.
You can also include this kind of thing in any additional stages:
The labels should not themselves contain causal ideas like 'due to...'. Delete or correct or add links if necessary.
Multiple stages
You can optionally separate your prompt into more than one stage, up to three stages, separated by
====Later I will give you a text. Your task is to identify the implicit causal network it tells you about. Understand the whole story: What factors influence what other factors? What are the longer causal chains and networks?
Describe the network by listing the main causal links in the text so that each cause is followed by >> and then its effect: cause >> effect.
.. [other instructions]…
====Good but maybe you made a few mistakes. Correct them.
Delete links for which there is insufficient evidence in the text.
Delete or correct links for which you invented or assumed causes or effects.
The labels should not themselves contain causal ideas like 'due to...'. Delete or correct or add links if necessary.
Is the direction of each link correct? If not, switch the order of cause and effect.
Edit your labels to make them as clear as possible for someone who never read the text.
Add any missing links.
If you are sure there are no links, print '!NO LINKS'.
Simply print out your corrected and complete list of links with no other comment.
====Good, but I think you missed some causal links.
You already identified some links between causal factors but there may be other links between other pairs of these factors which you missed. And you may have missed some antecedent causes or some further effects.
Go back and read line by line and identify ALL the missing links and print the complete correct list of links with no mistakes, no footnotes/annotations, and no commentary or summary.
You don’t have to worry about adding text like “The actual text is pasted below” etc as the app will do that for you.
These multiple stages are just like a conversation thread in ChatGPT or similar.
You can see the results of each stage in The Responses tab, but only the final result is actually fed into the app to create links.
You don’t have to use multiple stages, you can use just one without any
====.Three stages costs approximately 3* the price of one phase.
Coding named entities
this task is hard because we have to think about on the one hand giving background information to the coding AI and on the other hand what kind of labels we want:
readability for clients, ease of recoding in Manage Links, and suitability for embedding. different tasks with different requirements.
We should probably split our information into two corresponding parts.
A) Background Information for the coding AI
it is important to tell the coding AI that SONGOLAM = Assainissement pour tous - is a sanitation project in the Central South, financed by the European Union, becaue it might help it understand better.
but it is a separate problem what phrase it should use when actually coding this
but it is a separate problem what phrase it should use when actually coding this
B) Information for the coding AI on how to produce labels
We want the coding AI to use the same word or phrase for the same thing, e.g. different ways of talking about the same project or organisation.
Remember the coding AI can actually understand background knowledge and maybe bear it in mind, but the embedder is not genAI, it simply takes a word or phrase or paragraph and gives its numerical location on an incredible global map of meanings.
If you ask for labels in language X, make sure your explanations in this section also refer to language X: our preferred phrase should normally be in the same language as the other labels we ask it to make.
Remember the coding AI can actually understand background knowledge and maybe bear it in mind, but the embedder is not genAI, it simply takes a word or phrase or paragraph and gives its numerical location on an incredible global map of meanings.
If you ask for labels in language X, make sure your explanations in this section also refer to language X: our preferred phrase should normally be in the same language as the other labels we ask it to make.
Should we tell the coding AI to use special abbreviations or general language?
It's tricky. on the one hand we like the abbreviations because they are clear and we can easily recode variations of project names into the abbreviations.
if we use an abbreviation for say PFNL, the embeddings algorithm will not know where to position this except close to other phrases with PFNL.
Maybe this is what we want.
if we use an abbreviation for say PFNL, the embeddings algorithm will not know where to position this except close to other phrases with PFNL.
Maybe this is what we want.
Embeddings are a special problem
(This part is only relevant if you want to use auto clustering or magnetic labels, both of which use embeddings.)
If on the other hand PFNL might be one of several different product types with a whole range of different names, and we want to embed them as similar to one another, then we need to spell out the meaning.
If on the other hand PFNL might be one of several different product types with a whole range of different names, and we want to embed them as similar to one another, then we need to spell out the meaning.
It may be simplest to ask it to use an abbreviation, e.g.
For 'TreeAid', 'Tree Aid', 'TA' 'BB6' and similar, write 'BB6 project'
For 'Dutch International Development', 'Netherlands Development Organisation', 'Stichting Nederlandse Vrijwilligers' 'SNV' and similar, write 'SNV (NGO)'
For 'TreeAid', 'Tree Aid', 'TA' 'BB6' and similar, write 'BB6 project'
For 'Dutch International Development', 'Netherlands Development Organisation', 'Stichting Nederlandse Vrijwilligers' 'SNV' and similar, write 'SNV (NGO)'
Remember from a business point of view the overarching priority is often identifying each and every mention of an intervention and related interventions, and distinguishing these from unrelated interventions.
So for coding AI purposes and ordinary causal mapping, it is often simplest just to use abbreviations....
BUT if we do that, we have to understand that non-common abbreviations don't mean anything to the embedder
If we want them to mean something because we want STW and STC to be clustered close together because they stand for Save The Whales project and Save the Cetaceans Project, then we have a problem.
BUT if we do that, we have to understand that non-common abbreviations don't mean anything to the embedder
If we want them to mean something because we want STW and STC to be clustered close together because they stand for Save The Whales project and Save the Cetaceans Project, then we have a problem.
But even here, it might be better to have clear unambiguous abbreviations rather than some phrase because then it is easy to recode with Manage Links
Ideally I think we would tell the coding AI to make labels with both parts, e.g. 'STW (Save the Whales Project)' but I think this is hard for it and it may not be consistent.
Identifying links
You can provide any prompt you want and this will be applied to currently visible statements. BUT in order to actually identify links (which is the whole point), the output needs to include at least some lines including the “
>>” symbol, which we call the “double-arrow”.Each line of the form X >> Y will be converted to a link from X to Y.
Previously we have sometime asked for longer chains like X >> Y >> Z, and this should still work, but our current thinking is that individual links work best e.g.
X >> Y
Y >> Z
etc
Ensuring quotes are provided
All of our approach is about making sure that there’s always quotes and evidence behind the causal links that we’re identifying. So you could just say to ChatGPT, ‘please find some kind of causal map based on this entire set of transcripts’. And it would come out with something probably quite good, but you wouldn’t know what its evidence was for each of the different links. It would just do its own thing. That’s not really scientific and I’m not sure that as evaluators you could really justify doing that.
What we want is always to have evidence behind each of the causal links that it finds, which we do with the prompt.
Currently we do this with Slash style: We ask the AI to give us the whole quote at the end of the line, separated by four slashes.
In this style, it is easier to specify how to work with longer chains rather than individual links. And it is required when you send several statements in one batch.
Caveats
The top level map is always misleading after auto-coding without a codebook. The AI creates codes on the fly, so it can be quite random which happen to get mentioned more than once. If you are using auto-coding and want a top-level map, you need to then apply 🗃️ Canonical workflow and/or ✨ Transforms Filters: 🧲 Magnetic labels.
Limitations
Prompts can only be used to add information to factor labels, not link fields like the “hashtags” field.
Other information like quickfields e.g.
increased yields time:2013 and other factor tags are part of the factor label and so in principle can be added to the prompt. But we haven’t tried that.Consistency across factor labels
To improve the consistency of factor labels, several approaches can be considered:
- Preferred Factor Labels: give the AI a list of preferred factor labels, along with examples to clarify their usage.
- NER: you can do a kind of Named Entity Recognition - at the level of entities (eg people, places, organisations), giving it a vocabulary - words and phrases to recognise, not necessarily factor labels.
- Social Science Type: suggest to the AI to use a common “social sciences” vocabulary like:
- presence of resources
- lack of resources
- more/better income
- more/better motivation
- more/better support from peers
- … also use ~ for contrary factors
The end of your journey: a good pair of prompts
You don’t have to use a pair of prompts. But in this case, notice that Prompt 1 explicitly asks for causal chains and interconnected sets of links, ideally ending with an important outcome. So in this case the second prompt is useful to “mop up” anything missed by Prompt 2. This combination is good because if you just ask for any causal links or chains, the results tend to be more fragmented and less story-like.
Bear in mind that including a second prompt is about twice as expensive as a single prompt. Leave the second prompt blank if you don’t want to use it.
You can try tweaking the language e.g. to insist on using only your suggested factor labels, or in Prompt 1 to insist on causal chains which end in an important outcome, rather than suggesting it.
This is always a fine balance. You more you give specific instructions e.g. to find longer chains with specific contents, or to flag certain contents e.g.
!Gender, the more likely it is that your prompt will miss more of the links.Balancing link coverage and true positive rate
You want the coding to have a good true positive rate, to find all the links that are really there in the text.
But in your final reports you want good link coverage: your maps include most of the links.
If you have a prompt which allows too many factor labels which are not in the codebook, you’ll have a lot of work to recode these. If you don’t, you’ll have poor link coverage, and you’ll think, why did I bother crafting a prompt which succeeded in identifying all the links if those links are never actually used on the maps.
Duplicated links
If you are autocoding and notices some duplicate links, first try refreshing the page. Sometimes the duplications disappear after refreshing. But to make sure you don't have any more duplicates, you can check the tables.
On the tables tab,
- select links table
- add
source_idandquoteto the Fields
- select
bundlein the Grouping rows
- select
Count uniquein the ‘How to aggregate the fields’ dropdown list.
You will get a table like the one below:
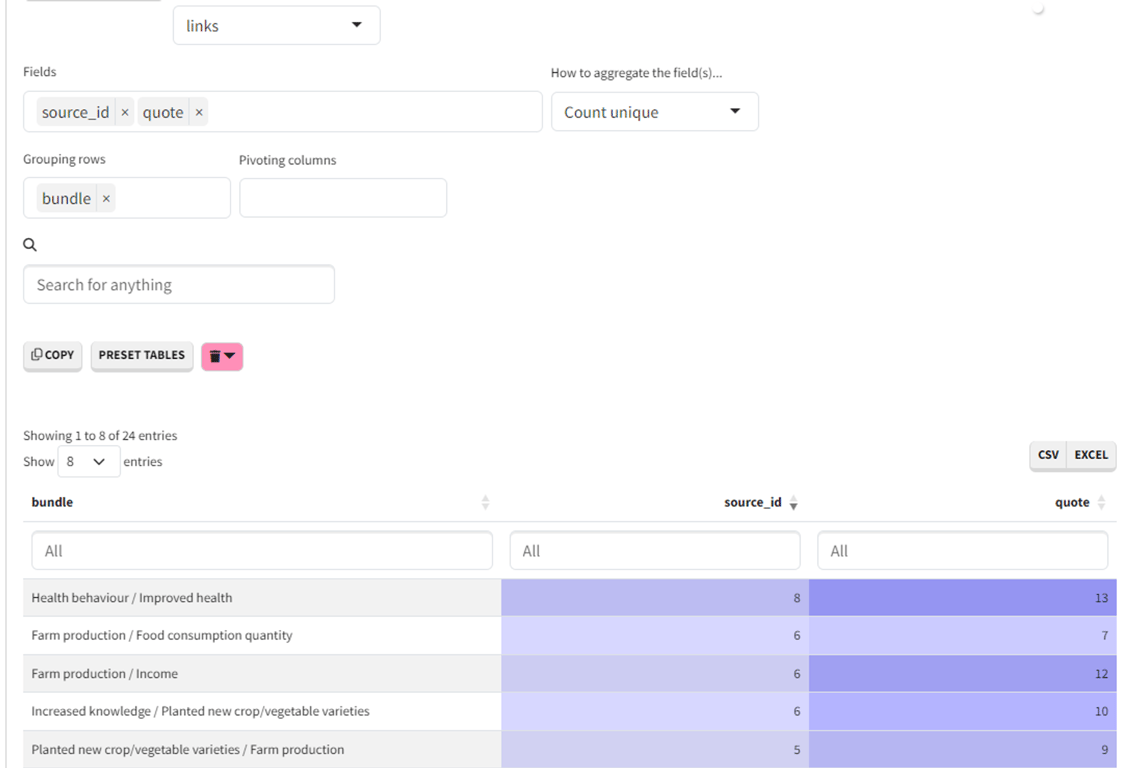
The number of unique links shouldn't be higher then the number of quotes, because this means that the same quote was used more than once for the same link, which means it is a duplication.
If after refreshing the page you still get duplicated links, contact us at hello@causalmap.app
Auto-coding using AI: writing the instructionsThe coding promptSentences coding versus phrases codingMultiple stagesCoding named entitiesA) Background Information for the coding AIB) Information for the coding AI on how to produce labelsEmbeddings are a special problemIdentifying linksEnsuring quotes are providedCaveats LimitationsConsistency across factor labelsThe end of your journey: a good pair of promptsBalancing link coverage and true positive rateDuplicated links